
SIS - Sistemas Instrumentados de Segurança - Uma visão prática - Parte 3

Introdução
Os Sistemas de Seguranças Instrumentados (SIS) são utilizados para monitorar a condição de valores e parâmetros de uma planta dentro dos limites operacionais e quando houver condições de riscos devem gerar alarmes e colocar a planta em uma condição segura ou mesmo na condição de shutdown.
As condições de segurança devem ser sempre seguidas e adotadas em plantas e as melhores práticas operacionais e de instalação são deveres dos empregadores e empregados. Vale lembrar ainda que o primeiro conceito em relação à legislação de segurança é garantir que todos os sistemas sejam instalados e operados de forma segura e o segundo é que instrumentos e alarmes envolvidos com segurança sejam operados com confiabilidade e eficiência.
Os Sistemas Instrumentados de Segurança (SIS) são os sistemas responsáveis pela segurança operacional e que garantem a parada de emergência dentro dos limites considerados seguros, sempre que a operação ultrapassar estes limites. O objetivo principal é se evitar acidentes dentro e fora das fábricas, como incêndios, explosões, danos aos equipamentos, proteção da produção e da propriedade e mais do que isto, evitar riscos de vidas ou danos à saúde pessoal e impactos catastróficos para a comunidade. Deve-se ter de forma clara que nenhum sistema é totalmente imune a falhas e sempre deve proporcionar mesmo em caso de falha, uma condição segura.
Durante muitos anos os sistemas de segurança foram projetados de acordo com os padrões alemães (DIN V VDE 0801 e DIN V 19250) que foram bem aceitos durante anos pela comunidade mundial de segurança e que culminou com os esforços para um padrão mundial, a IEC 61508, que serve hoje de guarda-chuva em seguranças operacionais envolvendo sistemas elétricos, eletrônicos, dispositivos programáveis para qualquer tipo de indústria. Este padrão cobre todos os sistemas de segurança que têm natureza eletromecânica.
Os produtos certificados de acordo com a IEC 61508 devem tratar basicamente 3 tipos de falhas:
- Falhas de hardware randômicas
- Falhas sistemáticas
- Falhas de causas comuns
A IEC 61508 é dividida em 7 partes das quais as 4 primeiras são mandatórias e as 3 restantes servem de guias de orientação:
- Part 1: General requirements
- Part 2: Requirements for E/E/PE safety-related systems
- Part 3: Software requirements
- Part 4: Definitions and abbreviations
- Part 5: Examples of methods for the determination of safety integrity levels
- Part 6: Guidelines on the application of IEC 61508-2 and IEC 61508-3
- Part 7: Overview of techniques and measures
Este padrão trata sistematicamente todas as atividades do ciclo de vida de um SIS (Sistema Instrumentado de Segurança) e é voltado para a performance exigida do sistema, isto é, uma vez atingido o nível de SIL (nível de integridade de segurança) desejável, o nível de redundância e o intervalo de teste ficam a critério de quem especificou o sistema.
A IEC 61508 busca potencializar as melhorias dos PES (Programmable Electronic Safety, onde estão incluídos os PLCs, sistemas microprocessados, sistemas de controle distribuído, sensores e atuadores inteligentes, etc.) de forma a uniformizar os conceitos envolvidos.
Recentemente vários padrões sobre o desenvolvimento, projeto e manutenção de SIS foram elaborados, onde já citamos a IEC 61508 (indústrias em geral) e vale citar também a IEC 61511, voltada as indústrias de processamento contínuo, líquidos e gases.
Na prática se tem visto em muitas aplicações a especificação de equipamentos com certificação SIL para serem utilizados em sistemas de controle, e sem função de segurança. Acredita-se também que exista no mercado desinformação, levando a compra de equipamentos mais caros, desenvolvidos para funções de segurança onde na prática serão aplicados em funções de controle de processo, onde a certificação SIL não traz os benefícios esperados, dificultando inclusive a utilização e operação dos equipamentos.Além disso, esta desinformação leva os usuários a acreditarem que têm um sistema de controle seguro certificado, mas na realidade eles possuem um controlador com funções de segurança certificado.
Com o crescimento do uso e aplicações com equipamentos e instrumentação digitais, é de extrema importância aos profissionais envolvidos em projetos ou no dia-a-dia da instrumentação que se capacitem e adquiram o conhecimento de como determinar a performance exigida pelos sistemas de segurança, que tenham o domínio das ferramentas de cálculos e as taxas de riscos que se encontram dentro de limites aceitáveis.
Além disso, é necessário:
- Entender as falhas em modo comum, saber quais os tipos de falhas seguras e não seguras são possíveis em um determinado sistema, como preveni-las e mais do que isto; quando, como, onde e qual grau de redundância é mais adequado para cada caso.
- Definir o nível de manutenção preventiva adequado para cada aplicação.
O mero uso de equipamentos modernos, sofisticados ou mesmo certificados, por si só não garante absolutamente nenhuma melhoria de confiabilidade e segurança de operação, quando comparado com tecnologias tradicionais, exceto quando o sistema é implantado com critérios e conhecimento das vantagens e das limitações inerentes a cada tipo de tecnologia disponível. Além disso, deve-se ter em mente toda a questão do ciclo de vida de um SIS.
Comumente vemos acidentes relacionados a dispositivos de segurança bypassados pela operação ou durante uma manutenção. Certamente é muito difícil evitar na fase de projeto que um dispositivo destes venha a ser bypassado no futuro, mas através de um projeto criterioso e que atenda melhor às necessidades operacionais do usuário do sistema de segurança, é possível eliminar ou reduzir consideravelmente o número de bypasses não autorizados.
Através do uso e aplicação de técnicas com circuitos de lógica fixas ou programáveis, tolerantes à falha e/ou de falha segura, microcomputadores e conceitos de software, hoje já se pode projetar sistemas eficientes e seguros com custos adequados a esta função.
O grau de complexidade de SIS depende muito do processo considerado. Aquecedores, reatores, colunas de craquamento, caldeiras, fornos são exemplos típicos de equipamentos que exigem sistemas de intertravamento de segurança cuidadosamente projetados e implementados.
O funcionamento adequado de um SIS requer condições de desempenho e diagnósticos superiores aos sistemas convencionais. A operação segura em um SIS é composta de sensores, programadores lógicos, processadores e elementos finais projetados com a finalidade de provocar a parada sempre que houver limites seguros sendo ultrapassados (por exemplo, variáveis de processos como pressão e temperatura acima dos limites de alarme muito alto) ou mesmo impedir o funcionamento em condições não favoráveis às condições seguras de operação.
Exemplos típicos de sistemas de segurança:
- Sistema de Shutdown de Emergência (ESD)
- Sistema de Shutdown de Segurança (SSD)
- Sistema de intertravamento de Segurança
- Sistema de Fogo e Gás
Veremos a seguir, em uma série de artigos, mais detalhes práticos envolvendo cálculos probabilísticos, conceitos de confiabilidade, falhas e segurança, SIS, etc.
Vimos no artigo anterior, na segunda parte, alguns detalhes sobre Engenharia de Confiabilidade. Veremos agora, sobre modelos usando sistemas em série e paralelo, árvores de falhas (Fault Trees), modelo de Markov e alguns cálculos.
Análise de Falhas – Árvore de Falhas (Fault Trees)
Existem algumas metodologias de análises de falhas. Uma delas e bastante utilizada é a análise da árvore de falhas (Fault Tree Analysis – FTA), que visa melhorar a confiabilidade de produtos e processos através da análise sistemática de possíveis falhas e suas conseqüências, orientando na adoção de medidas corretivas ou preventivas.
O diagrama da árvore de falhas mostra o relacionamento hierárquico entre os modos de falhas identificados. O processo de construção da árvore tem início com a percepção ou previsão de uma falha, que a seguir é decomposto e detalhado até eventos mais simples. Dessa forma, a análise da árvore de falhas é uma técnica top-down, pois parte de eventos gerais que são desdobrados em eventos mais específicos.
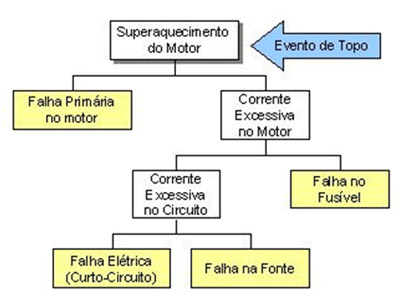
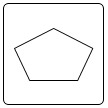
A seguir é mostrado um exemplo de um diagrama FTA aplicado a uma falha em um motor de elétrico. O evento inicial, que pode ser uma falha observada ou prevista, é chamado de evento de topo, e está indicado pela seta azul. A partir desse evento são detalhadas outras falhas até chegar a eventos básicos que constituem o limite de resolução do diagrama. As falhas mostradas em amarelo compõem o limite de resolução deste diagrama.
Figura 1 - Exemplo de FTA
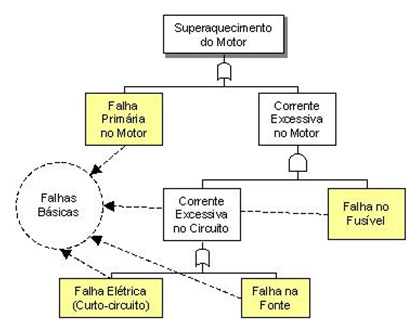
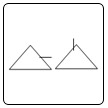
É possível adicionar ao diagrama elementos lógicos, tais como ‘e’ e ‘ou’, para melhor caracterizar os relacionamentos entre as falhas. Dessa forma é possível utilizar o diagrama para estimar a probabilidade de uma falha acontecer a partir de eventos mais específicos. O exemplo a seguir mostra uma árvore aplicada ao problema de superaquecimento em um motor elétrico utilizando elementos lógicos.
Figura 2 - Exemplo de FTA usando elementos lógicos
A análise da Árvore de Falhas foi desenvolvida no início dos anos 60 pelos engenheiros da Bell Telephone Company.
Símbolos Lógicos usados na FTA
A realização da FTA é uma representação gráfica da inter-relação entre as falhas de equipamentos ou de operação que podem resultar em um acidente específico. Os símbolos mostrados a seguir são usados na construção da árvore para representar está inter-relação.
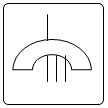
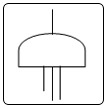
PORTA “OU”: indica que a saída do evento ocorre quando há uma entrada de qualquer tipo. PORTA“E”: indica que a saída do evento ocorre somente quando há uma entrada simultânea de todos os eventos. PORTA DE INIBIÇÃO: indica que a saída do evento ocorre quando acontece a entrada e a condição inibidora é satisfeita. PORTA DE RESTRIÇÃO: indica que a saída do evento ocorre quando a entrada acontece e o tempo específico de atraso ou restrição expirou. EVENTO BÁSICO: representa a FALHA BÁSICA do equipamento ou falha do sistema que não requer outras falhas ou defeitos adicionais. EVENTO INTERMEDIÁRIO: representa uma falha num evento resultado da interação com outras falhas que são desenvolvidas através de entradas lógicas como as acima descritas. EVENTO NÃO DESENVOLVIDO: representa uma falha que não é examinada mais, porque a informação não está disponível ou porque suas conseqüências são insignificantes. EVENTO EXTERNO: representa uma condição ou um evento que é suposto existir como uma condição limite do sistema para análise. TRANSFERÊNCIAS: indica que a árvore da falhas é desenvolvida de forma adicional em outras folhas. Os símbolos de transferência são identificados através de números ou letras. Figura 3 - Símbolos Lógicos usados na FTA

Modelos de Markov
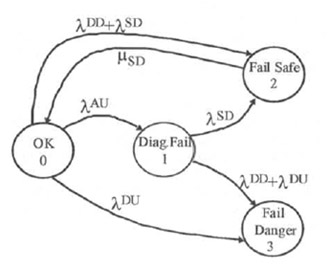
Um modelo de Markov é um diagrama de estado onde se identificam os diversos estados de falha de um sistema. Os estados são ligados por arcos identificados com as taxas de falha ou as taxas de reparo que levam o sistema de um estado para outro (vide figura 4 e figura 5).. Os modelos de Markov são conhecidos também como diagramas de espaço de estados ou diagramas de estado. O espaço de estados é definido como o conjunto de todos os estados em que o sistema pode se encontrar.
Figura 4 – Exemplo de modelo de Markov
Para um determinado sistema, um modelo de Markov consiste em uma lista dos estados possíveis desse sistema, os caminhos possíveis de transição entre os estados, e as taxas de falhas de tais transições. Na análise da confiabilidade das transições consistem geralmente de falhas e reparos. Ao representar um modelo de Markov graficamente, cada estado é representado como um “círculo", com setas indicando os caminhos de transição entre os estados, como mostrado na figura 4.
O método de Markov é uma técnica útil para modelar a confiabilidade de sistemas nos quais as falhas são estatisticamente independentes e as taxas de falha e reparo são constantes.
Entende-se como estado de um componente o conjunto de possíveis valores que seus parâmetros podem assumir. Estes parâmetros são chamados variáveis de estado e descrevem a condição do componente. O espaço de estados é o conjunto de todos estados que um componente pode apresentar.
O modelo de Markov de um verdadeiro sistema geralmente inclui um "full-up" do estado (ou seja, o estado com todos os elementos operacionais) e um conjunto de estados intermediários que representam uma condição de falha parcial, levando ao estado totalmente em falha, ou seja, o estado em que o sistema é incapaz de desempenhar a sua função de projeto. O modelo pode incluir caminhos de reparação de transição, bem como os caminhos de transição de falha. Em geral, cada caminho de transição entre dois estados reduz a probabilidade do estado que ele está partindo, e aumenta a probabilidade do estado em que está entrando, a uma taxa igual ao parâmetro de transição multiplicada pela probabilidade atual do estado de origem.
O fluxo de probabilidade total em um determinado estado é a soma de todas as taxas de transição para esse estado, cada um multiplicado pela probabilidade do estado na origem dessa transição. A saída de fluxo probabilidade de um dado estado é a soma de todas as transições que saem do estado multiplicado pela probabilidade daquele determinado estado. Para ilustrar, os fluxos de entrada e saída típica de um estado e de estados vizinhos estão representados na Figura 4.
Neste modelo todas as falhas são classificadas como falhas perigosas ou como falhas seguras. Uma falha perigosa é aquela que põe o sistema de segurança em um estado em que ele não estará disponível para parar o processo se isto vier a ser necessário. Uma falha segura é aquela que leva o sistema a parar o processo em uma situação onde não existe perigo. A falha segura é normalmente chamada de "trip” falso ou espúrio.
Os modelos de Markov incluem fatores de cobertura de diagnóstico para todos os componentes e taxas de reparos. Os modelos consideram que as falhas que não forem detectadas serão diagnosticadas e reparadas por testes de prova periódicos (proof tests).
Os modelos de Markov incluem ainda taxas de falhas associadas a falhas funcionais e falhas comuns de hardware.
A modelagem do sistema deve incluir todos os tipos possíveis de falhas e estas podem ser agrupadas em duas categorias:
- Falhas físicas
- Falhas funcionais
As falhas físicas são as que ocorrem quando a função desempenhada por um módulo, um componente, etc., apresenta um desvio em relação à função especificada devido à degradação física.
As falhas físicas podem ser falhas por envelhecimento natural ou falhas provocadas pelo ambiente.
Para se utilizar às falhas físicas nos modelos de Markov deve-se determinar a causa das falhas e seus efeitos nos módulos, etc. As falhas físicas devem ser categorizadas como falhas dependentes ou independentes.
Falhas independentes são aquelas que nunca afetam mais do que um módulo, enquanto que as falhas dependentes podem vir a causar a falha de vários módulos.
As falhas funcionais são as que ocorrem quando o equipamento físico está em operação embora sem capacidade de desempenhar a função especificada devido a uma deficiência funcional ou a um erro humano. Exemplos de falhas funcionais são: erros de projeto do sistema de segurança, de software, na ligação do hardware, erros de interação humana e erros de projeto do hardware.
Nos modelos de Markov as falhas funcionais são separadas em falhas seguras e em falhas perigosas. Supõe-se que uma falha funcional segura resultará em um trip espúrio. De modo similar, uma falha funcional perigosa resultará em um estado de falha-para-atuar, isto é, aquela que o sistema não estará disponível para parar o processo. A avaliação da taxa de falha funcional deve levar em consideração muitas causas possíveis, como por exemplo:
- Erros de projeto do sistema de segurança
Aqui se incluem erros de especificação lógica do sistema de segurança, escolha de arquitetura inadequada para o sistema, seleção incorreta de sensores e atuadores, erros no projeto da interface entre os PLCs e os sensores e atuadores.
- Erros de implementação do hardware
Esses erros incluem erros na ligação dos sensores e dos atuadores aos PLCs. A probabilidade de erro cresce com a redundância de E/S se o usuário tiver que ligar cada sensor e cada atuador a vários terminais de E/S. A utilização de sensores e atuadores redundantes também acarretará em uma maior probabilidade de erros de ligação.
- Erros de software
Esses erros incluem os erros em softwares desenvolvidos tanto pelo fornecedor quanto pelo usuário. Os softwares de fornecedores tipicamente incluem o sistema operacional, as rotinas de E/S, funções aplicativas e linguagens de operação. Os erros de software do fornecedor podem ser minimizados ao se assegurar um bom projeto de software e a observância dos procedimentos de codificação e testes. A realização de testes independentes por outras organizações também pode ser muito útil.
Os erros de software desenvolvidos pelo usuário incluem erros no programa aplicativo, diagnósticos e rotinas de interface do usuário (displays, etc.). Engenheiros especializados em software de sistemas de segurança podem ajudar a minimizar os erros de software do usuário. Deve-se também realizar testes exaustivos dos softwares.
- Erros de interação humana
Aqui se incluem os erros de projeto e de operação da interface homem-máquina do sistema de segurança, os erros cometidos durante testes periódicos do sistema de segurança e durante a manutenção de módulos defeituosos do sistema de segurança. Os erros de manutenção podem ser reduzidos através de um bom diagnóstico do sistema de segurança que identifique o módulo defeituoso e que inclua indicadores de falha nos módulos defeituosos. Vale lembrar aqui que não existe um diagnóstico perfeito ou a prova de falhas.
- Erros de projeto do hardware
Entre esses erros, incluem-se os erros do projeto de fabricação dos PLCs, sensores e atuadores, bem como os erros do usuário na interface entre o sistema de segurança e o processo.
Em configurações redundantes de PLCs, sensores e elementos de atuação, algumas falhas funcionais podem ser reduzidas através da utilização de diversos hardwares e/ ou softwares.
As falhas dependentes devem ser modeladas de modo diferente, já que é possível que ocorram falhas múltiplas simultaneamente. Do ponto de vista da modelagem, as falhas dependentes dominantes são falhas de causa comum. As falhas de causa comum são o resultado direto de uma causa básica comum. Um exemplo disso é a interferência de rádio freqüência que causa a falha simultânea de módulos múltiplos. A análise desse tipo de falhas é bastante complexa e exige um profundo conhecimento do Sistema, tanto em nível de hardware e de software quanto do próprio ambiente.
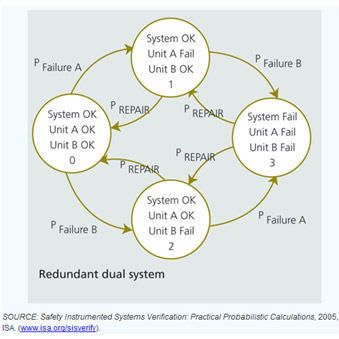
Figura 5 – Exemplo de modelo de Markov em sistema redundante
Certamente com equipamentos e ferramentas certificadas de acordo com o padrão IEC 61508 se tem o conhecimento das taxas de falhas dos produtos facilitando cálculos e arquiteturas de segurança.
Conclusão
Em termos práticos o que se busca é a redução de falhas e conseqüentemente a redução de paradas e riscos operacionais. Busca-se o aumento da disponibilidade operacional e também em termos de processos, a minimização da variabilidade com conseqüência direta no aumento da lucratividade.
Nos próximos artigos desta série veremos mais detalhes sobre SIS. Na quarta parte veremos um pouco sobre o Processo de Verificação de SIF.
Autor
- César Cassiolato
Referências
- IEC 61508 – Functional safety of electrical/electronic/programmable electronic safety-related systems.
- IEC 61511-1, clause 11, " Functional safety - Safety instrumented systems for the process industry sector - Part 1: Framework, definitions, system, hardware and software requirements", 2003-01
- William M. Goble, Harry Cheddie, "Safety Instrumented Systems Verification: Practical Probabilistic Calculation"
- ESTEVES, Marcello; RODRIGUEZ, João Aurélio V.; MACIEL, Marcos. Sistema de intertravamento de segurança, 2003.
- Sistemas Instrumentados de Segurança - César Cassiolato
- “Confiabilidade nos Sistemas de Medições e Sistemas Instrumentados de Segurança” - César Cassiolato
- Manual LD400-SIS
- Sistemas Instrumentados de Segurança – Uma visão prática – Parte 2, César Cassiolato
- http://www.numa.org.br/conhecimentos/conhecimentos_port/pag_conhec/FTA.htm

Links Relacionados:
- Confira a lista de Artigos Técnicos da SMAR: https://www.smar.com/pt/artigos-tecnicos
- PROFIBUS: https://www.smar.com/pt/artigos-tecnicos-profibus
Soluções Confiáveis

